TheFeed.press: Data and then?
I was checking out the MongoDB compass app this morning, using it to explore data from thefeed.press database. Here is what it looks like:
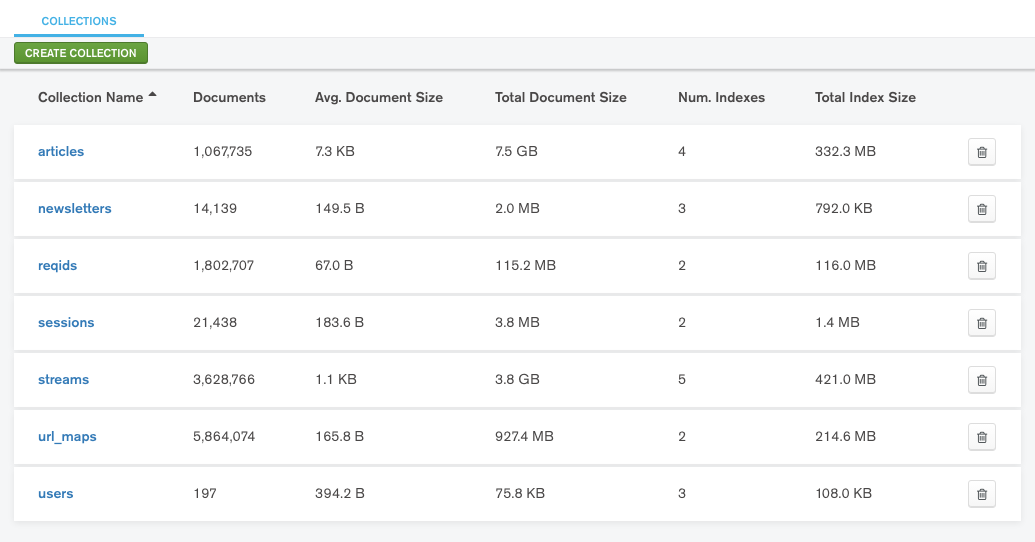
Notice the size of the articles and streams. And this is only from just over a month worth of data (I currently drop article data > a month as recommended by @akamaozu). Was I surprised at the data size? No. I know TFP (TheFeed.press) pulls a lot of articles as I mentioned in an earlier post. Question though is, what else can I do with the data?
Text Classification?
Most times, I find only one link in the email that really matches my interest and I click to see it. The others I discard. It’ll be good if that percentage can go up. Maybe I need to clean up my Twitter TL?
source: tgh.typeform.com/to/tGmcMq
For a while now, a feature I have been looking to add is automatically categorising articles. By matching categories with what users are reading (thanks to Mailgun click events + Suet), articles in a user’s fav categories can be prioritised in newsletters and the web feed. This will definitely bump up newsletter open rates (from ~ 37%) and CTR (from ~12%).
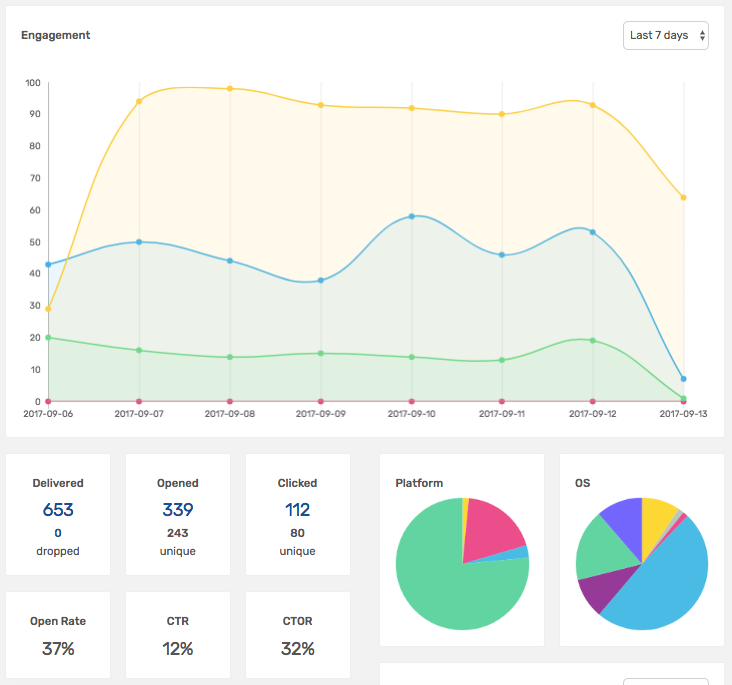 source: suet.co
source: suet.co
The bad news? Text classification isn’t an easy feat, especially not at TFP’s current scale and resources. I haven’t done any “code” work but I have explored a couple of ideas in my head.
Naives Bayes
I have explored Naives Bayes before. Details here and here. I have been looking at how effective it is for big data classification though but yet to make up my mind. There is also no easy way to test this without having to do some code work. For example, most good [Node.js] libraries I saw store and process the data in memory. I will probably have to write one myself.
Neural Network (NN)
A little understanding of how NN works will convince you given enough data for training, it will provide accurate results. I have also ran few experiments on it and it does provide accurate results. However, where the challenge lies is normalising words (converting the words to numerical value) for the input layer.
There are a couple of ways to do this. One interesting one is bag of words (BOW). However, for large dictionary of words, as with TFP articles, scaling BOW will be an issue. There is a Hashing Trick to deal with this but I’m really not convinced about it. I will take time to review other ways to normalise the words.
TF-IDF
TF-IDF can give important words in the document. That alone is not a big deal but it can be a starting point. For example, instead of running Naives Bayes or NN on all words in the document, it can be done on only the results from tf-idf. A process that can further increase the result will be:
Strip stop words and lower case words of length less than a threshold -> TF-IDF -> Classification Algorithm (Naives Bayes, NN, etc)
What else?
So far, I’ve only talked about classification. I believe there are more interesting things that can be done with the data. Sentiment Analysis? Trending words/topics? These are things I hope to explore once I have the time. If you have other ideas, do let me know. I am @kehers on Twitter.